【杂谈】SRA/GEO数据库编号层级
在学习过程中时,遇到了很多让人头大的公共数据库编号,故在这里做一个简单的梳理和存档。
1. NCBI Sequence Read Archive (SRA)
“raw sequence data files”
SRA 数据库包含实验的原始序列数据,适用于自己想下载并自行重新分析数据的情况。它们一般都通过一个共同的生物项目 ID 绑定在一起。
SRA中的编号有:
- SRP (SRA Project): 代表SRA中的研究或项目编号。
- SRS (SRA Sample) : 代表某个项目中的一个特定的样本。
- SRX (SRA Experiment): 表示一个特定的实验。
- SRR (SRA Run): 指一个特定的测序运行,是数据的实际来源。我们下载的数据通常就是以SRR开头的。
其中的关系可以由下面这张图表示:
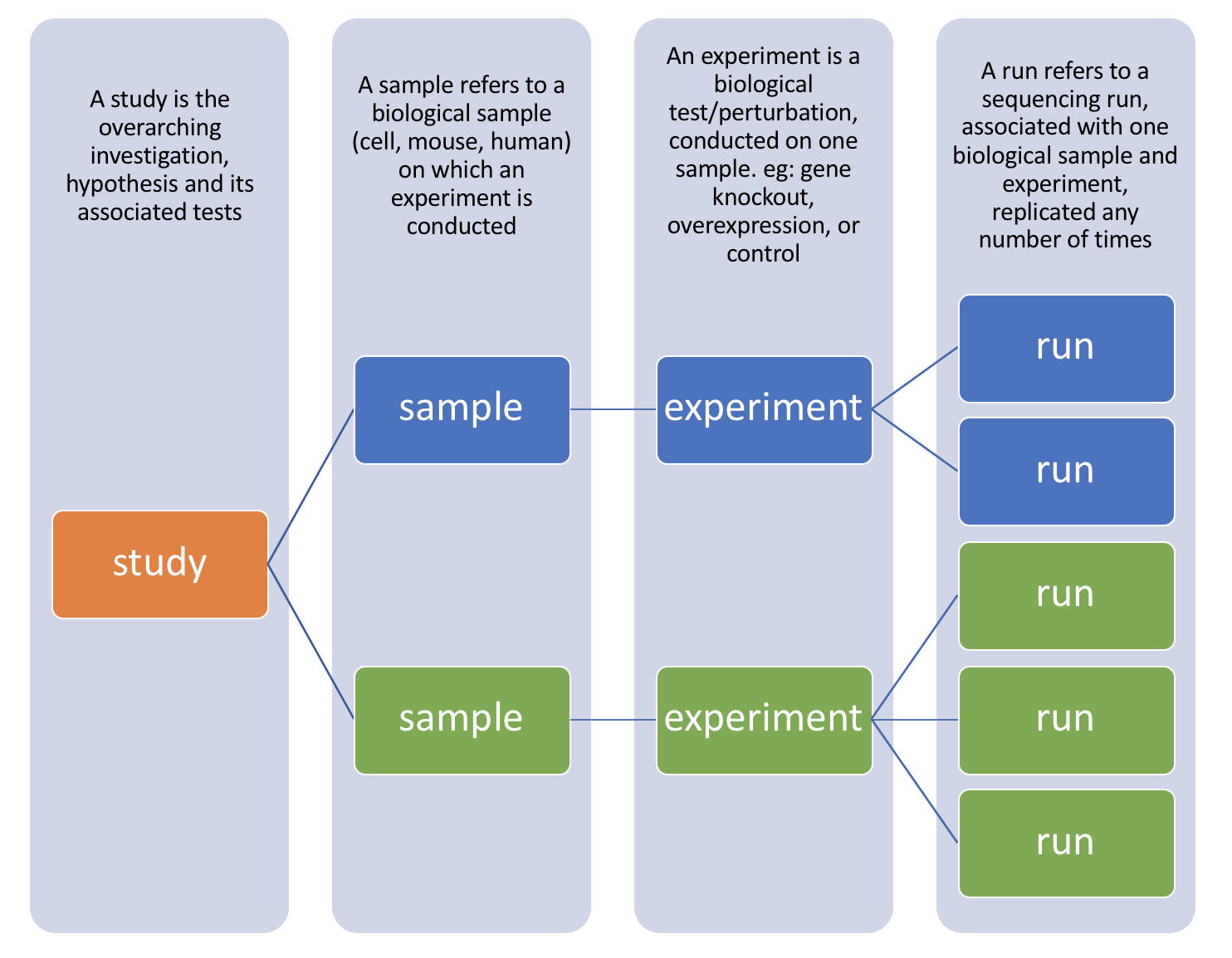
来源:[Accessing public genomic data: SRA | Accessing Public Genomic Data (hbctraining.github.io)] (https://hbctraining.github.io/Accessing_public_genomic_data/lessons/downloading_from_SRA.html)
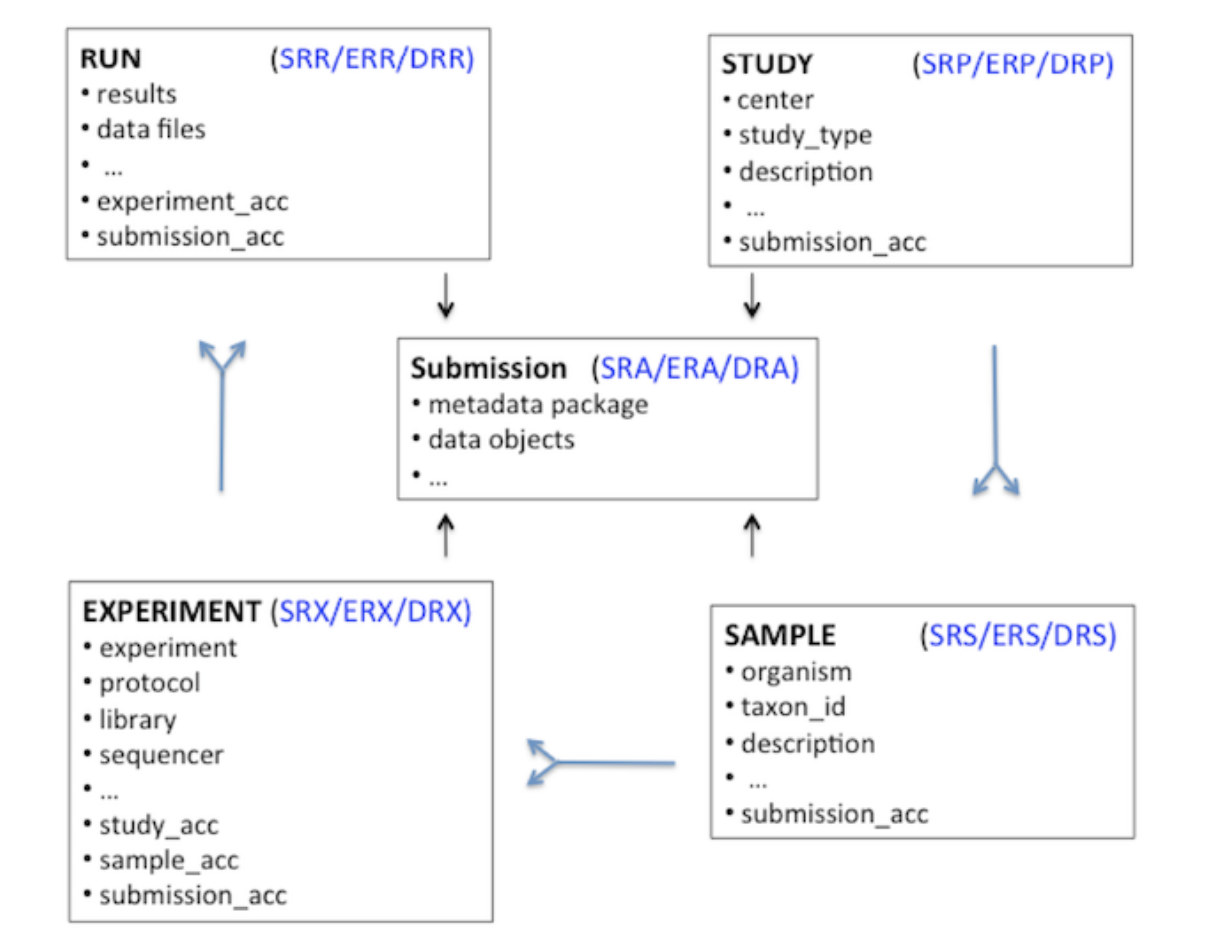
来源:[SRAdb.pdf (bioconductor.org)]
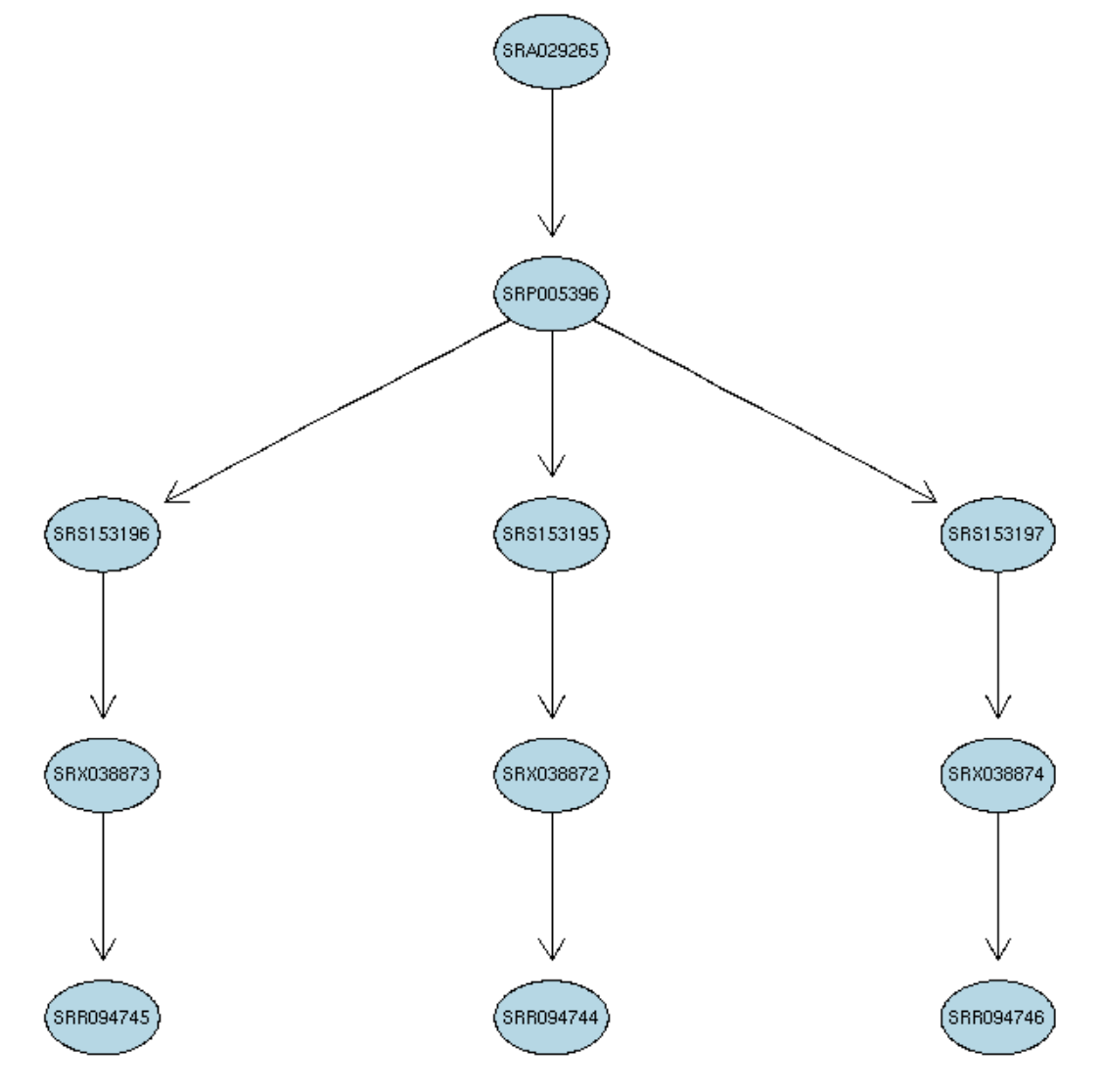
举例来说,就是这样的:
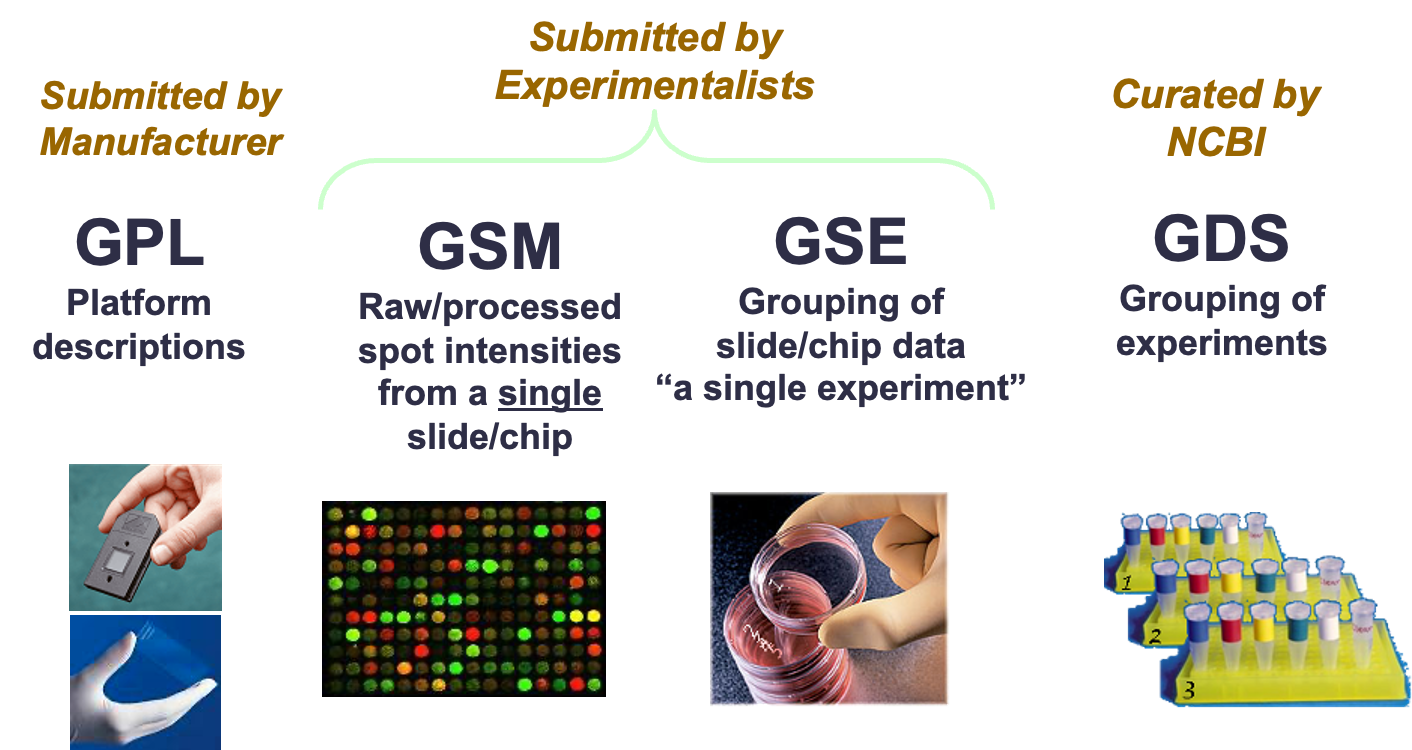
2. NCBI Gene Expression Omnibus (GEO)
“processed sequence data files”
GEO 包含与特定实验相关的数据,在大多数情况下,这些数据是经过处理的数据(例如,经过一个或多个分析步骤,如修剪、与参考文献比对、R/BioC 等)。这些文件都会绑定到特定的汇编版本以及与之相关的任何内容(注释等)。
GEO有四种类型的数据:
-
Platform (GPL) = the technology used and the features detected.
用于描述用于实验的技术平台,如特定类型的芯片或测序技术。
-
Series (GSE) = defines a set of samples and how they are related.
代表一个数据系列,包含多个样本(GSM)
-
Sample (GSM) = preparation and description of the sample.
指一个单独的生物学样本,包含特定的基因表达数据。
-
DataSets (GDS) = sample data collections assembled by GEO staff.
GEO 工作人员收集的样本数据。GDS 包含了跨多个样本的基因表达数据,这些数据已被处理以便于比较和分析。例如,数据可能已经被归一化,以消除不同实验条件或平台带来的偏差。